AI Is Getting Better at Everything—Including Being Exploited
As AI models become more capable and obedient, safety improvements struggle to keep pace. The GPT-5.1 safety score drop reveals a structural problem: capability and attack surface scale faster than safety.
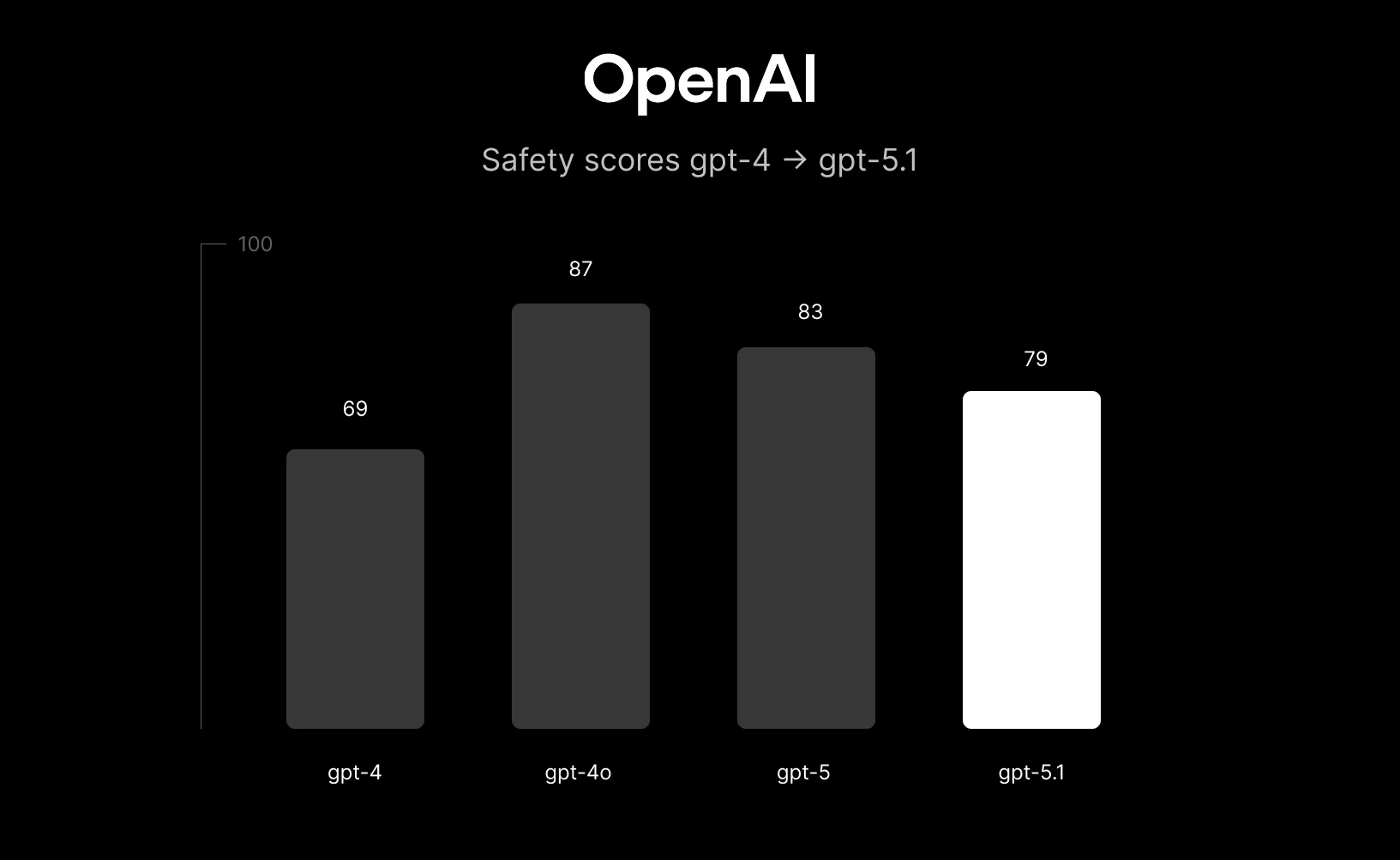
Take a look at the chart above.
On one axis: OpenAI’s frontier models – GPT-4, GPT-4o, GPT-5, GPT-5.1.
On the other: an aggregate “safety score.”
The curve is not what you’d hope for. From GPT-4 to GPT-4o and GPT-5, safety scores climb. Then GPT-5.1 drops.
If you squint, it looks like exactly the thing we all worry about: AI keeps getting better at everything… except not hurting us.
In this post I want to unpack why that pattern actually makes sense—and why it’s not just an OpenAI problem, but a structural one for anyone building on frontier models.
Capability and obedience scale faster than safety
The entire modern LLM stack is optimized to make models:
- More capable – better reasoning, more tools, longer context.
- More obedient – better at following instructions and matching user intent.
Safety training is then layered on top as a set of constraints: “do what the user wants… unless it’s harmful.”
As models scale, the “do what I want” gradient gets stronger. They understand more context, follow more subtle instructions, and can infer what you meant even if you didn’t say it clearly.
That’s great when you’re asking for a refactored codebase or a product roadmap.
It’s less great when an attacker carefully wraps a malicious request in a long, friendly, seemingly benign prompt.
Recent safety benchmarks show this clearly: models like GPT-4 are almost perfectly safe when you ask them for something obviously disallowed (“teach me how to build X”). But when the same harmful intent is expressed via multiple-choice questions, role-play, or jailbreak preambles, failure rates jump by an order of magnitude. The better a model is at following nuanced instructions in long context, the more often those clever prompts win.
That is exactly the dynamic the chart is picking up: as the “assistant” persona gets warmer and more helpful from GPT-5 to GPT-5.1, you’d expect some safety metrics to move in the wrong direction unless safety work grows even faster.
Agentic models increase the blast radius
A second, quieter shift is happening at the same time: models aren’t just chatbots anymore. They’re agents.
Frontier models are increasingly wired into:
- Browsers and search
- Code execution environments
- File systems and vector stores
- Business tools (CRMs, help desks, CI/CD, etc.)
From a safety perspective, this changes the game.
A jailbreak on an older, purely conversational model mostly means “it said something it shouldn’t have.” Annoying, reputationally bad, but contained.
A jailbreak on a tool-using agent can mean:
- Data exfiltration from internal systems via prompt injection
- Unauthorized actions (“book this”, “delete that”, “open this ticket”)
- Silent manipulation of internal workflows (changing configs, editing docs, modifying code)
Security researchers are already seeing this in the wild. Tool-using agents built on GPT-4-class models can be compromised by indirect prompt injection at non-trivial rates, especially when they browse the web or ingest untrusted data. And once the model has tools, each successful jailbreak has real-world side effects: API calls, system changes, outbound messages.
So even if a provider keeps the textual safety rate “roughly flat” between generations on their internal benchmarks, the expected damage of a failure has gone up, simply because the systems are more powerful and more connected.
Offense is also using frontier models
Another reason the GPT-5.1 drop doesn’t surprise us: attackers are using the same models we are.
- Red-teamers are fine-tuning models specifically to generate jailbreak prompts.
- Adversarial research shows that once you have a model that understands prompts very well, you can use it to search the space of possible jailbreaks more efficiently.
- These adversarial prompts tend to transfer: jailbreaks discovered against one model will often work, with minor edits, against another.
That means that even if OpenAI (or Anthropic, or anyone else) is steadily improving their safety stack, the effective risk as seen in the wild can still rise, because the offensive tools are scaling on the same curve.
This again matches the chart: GPT-5.1 is launched into an environment with more sophisticated prompt-injection toolkits, more jailbreaking communities, and more agentic use cases. Of course its observed safety score looks worse.
Safety metrics are noisy—and that’s a problem too
One more subtle point: how we measure safety can move the needle almost as much as what the model is actually doing.
Safety scores can be affected by:
- The style of the model (short vs. verbose, dry vs. empathetic)
- How the evaluation is phrased (direct harm vs. “evaluate this text” vs. multiple-choice)
- Whether an LLM or a human is doing the judging
- Which risks get weighted: speech vs. action, toxicity vs. self-harm vs. jailbreakability
OpenAI’s own GPT-5.1 system card explicitly notes that on some internal benchmarks 5.1 is more robust to jailbreaks than 5, but does worse on things like mental-health conversations and emotional over-reliance. Compress that trade-off into one number and you can very easily get a visible “drop” without any single catastrophic regression.
From a security engineering standpoint, that doesn’t make the problem less real. If anything, it’s worse: it means organizations are making deployment decisions based on oversimplified dashboards that hide a lot of nuance about which risks got better and which got worse.
What this means if you’re building on these models
For us at Superagent, the takeaway is not “don’t use the latest models.” The takeaway is:
Assume that capability and attack surface are scaling faster than safety, and design your systems accordingly.
Concretely, that looks like:
- Treating the model as an untrusted component in the architecture, not as an all-knowing oracle.
- Isolating tools and permissions; giving the agent the minimum necessary access for each task.
- Adding defense-in-depth: content filters, policy enforcement, and monitoring outside the model, not just via system prompts.
- Testing agents with adversarial prompts and untrusted inputs before they touch production data.
The story the chart tells—from GPT-4 to GPT-5.1—isn’t that AI safety is hopeless. It’s that we’re now firmly in a regime where “make the model smarter” is easy, and “make the system safer under attack” is the hard, engineering-heavy part.
That’s the gap the ecosystem needs to close. And right now, the numbers suggest the gap is still widening.