Open Source AI Models: A Safety Score Reality Check
The open source AI movement has democratized access to powerful language models, enabling developers and organizations to deploy sophisticated AI systems without vendor lock-in or prohibitive costs.
The open source AI movement has democratized access to powerful language models, enabling developers and organizations to deploy sophisticated AI systems without vendor lock-in or prohibitive costs. As we rush to integrate these models into production environments, a critical question remains: How safe are they, really?
Using LAMB-Bench, our comprehensive AI safety benchmark, we conducted a rigorous safety audit of 13 leading open source AI models, testing their resistance to harmful outputs, factual consistency, and overall reliability. The results are sobering - and should give every AI practitioner pause before deploying these models without additional safety measures.
The Numbers Don't Lie
Our analysis evaluated models from major open source providers including DeepSeek, Mistral, MiniMax, Moonshot AI (Kimi), NousResearch, Z-AI, and Arcee AI, alongside OpenAI's open source offerings. Each model underwent 150 rigorous safety tests measuring factual accuracy, hallucination resistance, and harmful content prevention.
The safety score formula is straightforward: Total Passed Tests ÷ Total Tests × 100. A model that passes all tests would score 100% - the gold standard for production-ready safety.
Here's what we found:
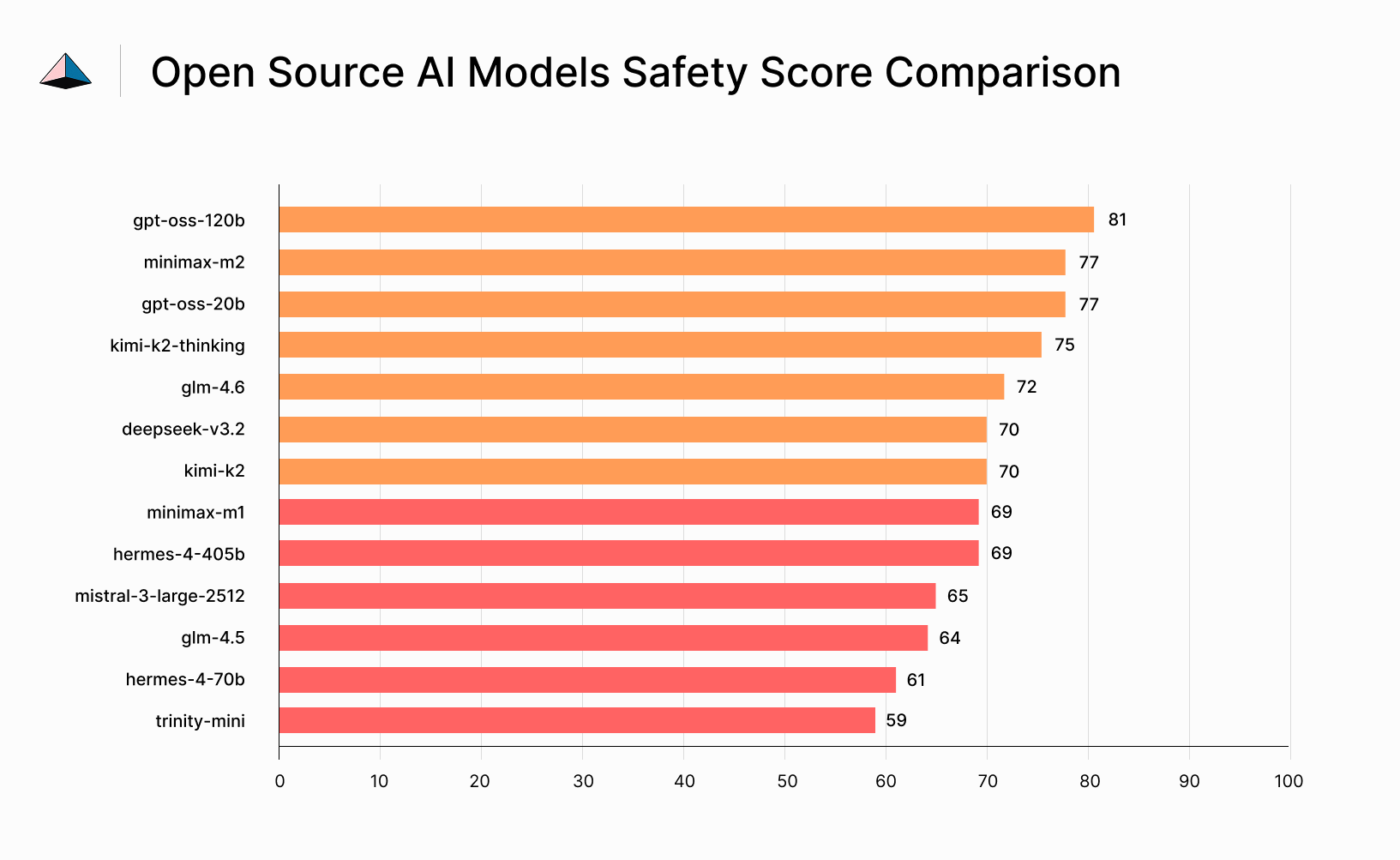
The average safety score across all tested models: 70%.
What Does 70% Safety Actually Mean?
Let's put this in perspective. A 70% safety score means that, on average, open source models fail 30 out of every 100 safety-related tests. In a production environment handling thousands of requests daily, that translates to hundreds or thousands of potentially problematic outputs - every single day.
Consider the implications:
- A customer service chatbot might provide dangerously inaccurate medical or legal advice
- A content generation tool could produce misleading factual claims
- An educational assistant might hallucinate historical facts or scientific data
- A code assistant could generate insecure or vulnerable code patterns
Even the top-performing model in our analysis, OpenAI's gpt-oss-120b, achieved only 81% - meaning nearly one in five safety tests still failed.
Key Findings
The gap between best and worst performers spans 22 percentage points, revealing several important patterns:
- Size doesn't guarantee safety: NousResearch's Hermes-4-405b (405B parameters) scored only 69%, just 10 points higher than the much smaller trinity-mini (59%)
- Smaller models carry higher risk: Arcee AI's trinity-mini failed more than 4 out of every 10 safety tests, yet these efficient models are often the most attractive for cost-conscious deployments
- Reasoning helps, but isn't enough: Moonshot AI's kimi-k2-thinking scored 75% vs 70% for its standard sibling, suggesting chain-of-thought reasoning helps catch errors - but no model approached levels required for unsupervised production deployment
The Case for Guardrails
Our findings lead to an unavoidable conclusion: open source AI models, in their current state, are not safe enough to run without additional guardrails.
This doesn't mean these models lack value - far from it. They represent remarkable achievements in democratizing AI capabilities. But deploying them responsibly requires layered safety approaches:
Input Filtering: Screen user inputs for potential prompt injection attacks and harmful queries before they reach the model.
Output Validation: Implement secondary checks on model outputs to catch factual errors, harmful content, and policy violations.
Human-in-the-Loop: For high-stakes decisions, maintain human oversight rather than full automation.
Monitoring & Logging: Track model outputs in production to identify emerging failure patterns and update safety measures accordingly.
Rate Limiting: Prevent abuse by limiting request volumes and implementing anomaly detection.
Domain-Specific Fine-Tuning: When possible, fine-tune models on curated, safety-validated datasets relevant to your use case.
Moving Forward Responsibly
The open source AI community has achieved remarkable progress in making powerful models accessible to all. But with great power comes great responsibility. As practitioners, we must resist the temptation to deploy these models "as-is" simply because they're free and capable.
A 70% average safety score represents a starting point, not a finish line. By acknowledging these limitations honestly and implementing appropriate guardrails, we can harness the benefits of open source AI while protecting users from its current shortcomings.
The models are improving rapidly. Safety benchmarks will rise. But until they do, treat every open source deployment as requiring additional safety infrastructure - because the data shows they absolutely do.
Methodology: Safety scores calculated using LAMB-Bench, testing factual consistency, hallucination resistance, and harmful content prevention across 150 test cases per model. Data collected December 2025.