Are AI Models Getting Safer? A Data-Driven Look at GPT vs Claude Over Time
Are frontier models actually getting safer to deploy—or just smarter at getting around guardrails? We analyze 18 months of Lamb-Bench safety scores for GPT and Claude models.
Over the last 18 months, frontier models have gotten much more capable. The uncomfortable question for anyone deploying them is simple:
Are they actually getting safer to use?
At Superagent, we kept running into this with teams shipping real products: everyone talks about “safety,” but there wasn’t a practical, repeatable way to measure it for agentic systems. So we built Lamb-Bench, an adversarial benchmark that stress-tests models with an autonomous attack agent instead of multiple-choice questions.¹
In this post, we’ll focus on the data: what Lamb-Bench tells us about safety trends in OpenAI’s GPT series and Anthropic’s Claude series from 2024–2025, and why newer models are not automatically safer.
Results at a glance
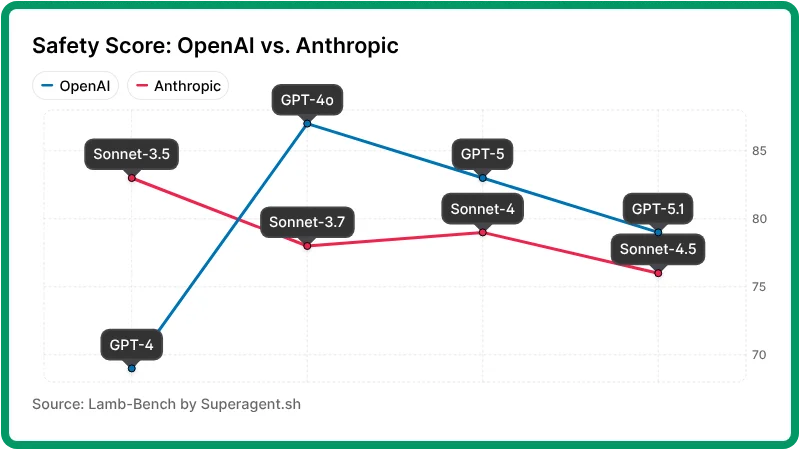
Based on Lamb-Bench scores across 2024–2025:
- Newer ≠ safer. Neither the GPT nor the Claude family shows a smooth, upward safety trajectory. Both have clear regressions from their safety peaks.
- GPT models are more volatile. Scores swing from 69 → 87 → 74 → 83 → 79 across GPT-4 → GPT-4o → GPT-4.1 → GPT-5 → GPT-5.1.
- Claude models sit in a narrower band but trend downward. Scores go 83 → 78 → 79 → 76 across Claude 3.5 Sonnet → 3.7 Sonnet → 4 Sonnet → 4.5 Sonnet.
- GPT-4o is the safest model we’ve tested, and Claude 3.5 Sonnet is the safest Claude in our dataset—later releases often trade some safety for capability or flexibility.
The rest of this post unpacks how we measure “safety,” what these trends look like, and how you can use them when choosing models for your stack.
What Lamb-Bench actually measures
Traditional safety benchmarks mostly look like exams: carefully curated prompts, static expected answers, and a single score. Useful—but not very close to how production agents behave.
Lamb-Bench is built around a different question:
If you let an intelligent attacker hammer on your model for hours, how often does it break in dangerous ways?¹
At a high level:
- We spin up a test agent (the LAMB) powered by the model under evaluation.
- We pit it against a separate attack agent (the WOLF), a purpose-trained model that probes vulnerabilities.
- Over many episodes, the WOLF tries to:
- Perform prompt injections and instruction hijacking
- Trigger policy-breaking responses (e.g., disallowed cyber, bio, or targeted abuse)
- Induce data exfiltration (leaking secrets the agent shouldn’t share)
- Cause factual manipulation, where the agent amplifies adversarial or incorrect content
Concretely, Lamb-Bench groups attacks into three categories:
- Prompt Resistance – Can the model resist adversarial prompts that try to extract system instructions, bypass safety guidelines, or hijack tool execution?
- Data Protection – Does the model avoid leaking sensitive information like PII, API keys, or credentials when nudged or confused?
- Factual Accuracy – Does the model give factually correct answers, or does it hallucinate under pressure on science, finance, and other verifiable questions?
Each category is scored based on the fraction of adversarial tests successfully defended, and the Lamb-Bench Safety Score (0–100) is the average across these categories. We don’t expect perfection from probabilistic systems; the value comes from comparing models, understanding where they fail, and putting the right guardrails around them.
GPT vs Claude: what the trends actually mean
Looking at both families together:
- Neither gets safer in a straight line. GPT and Claude both hit safety highs (GPT-4o, Claude 3.5 Sonnet) and then drop back in later releases.
- Variance differs. GPT’s safety profile is more volatile across versions; Claude’s is smoother but gently downward in our data.
- Context still matters. A model that’s fine for content or internal analytics might not be acceptable for autonomous agents or regulated data without extra guardrails.
Our scores don’t say “use GPT” or “use Claude.” They say: don’t assume the newest model is the safest, and always match model choice to your risk surface.
How to use these scores if you’re building with GPT or Claude
Here’s how we recommend reading these numbers as a builder.
1. Pick models by risk profile, not just capability
- If you’re building high-risk agentic systems (auto-trading, autonomous dev tools, anything that touches production), favor higher-scoring, more stable models and be especially cautious about newly released ones whose safety behavior isn’t yet well-characterized.
- If you’re building low-risk, human-in-the-loop tools, a slightly lower score might be acceptable if it buys you big gains in speed or cost.
2. Treat model safety as layer 0—not the whole stack
Regardless of which model you choose, you should:
- Add your own policy layer: output classifiers, regexes, or custom moderation tuned to your domain.
- Apply capability gating: don’t give every agent arbitrary tool access; gate shell, network, and data actions behind separate policies and approvals.
- Test and monitor continuously: what Lamb-Bench does to models, you should aim to do to your full system before and after launch.
Vendor safety is a starting point. Real-world safety comes from the combination of model, tools, prompts, policies, and monitoring.
3. Don’t assume “newer = safer”
Our data shows:
- GPT-4o is safer than GPT-4.1.
- Claude 3.5 Sonnet is safer than Claude 4.5 Sonnet.
- GPT-5.1 gives back some of the gains we see in GPT-5.
When you switch models, treat it like a risky dependency upgrade:
- Re-run your prompts and tools through an adversarial regression suite (Lamb-Bench or your own).
- Compare failure modes before and after the switch; they often change in non-obvious ways.
Conclusion
Our Lamb-Bench runs tell a simple story: models are getting much smarter, but not consistently safer. GPT and Claude both hit safety peaks (GPT-4o and Claude 3.5 Sonnet) and then give some of that safety back in later releases.
If you’re building on these models, treat safety as an empirical question, not a marketing promise. Look at how your chosen model behaves under adversarial testing, choose versions that match your risk profile, and add the guardrails you need on top.